|
Matteo Farina
I am an ELLIS PhD Student 🇪🇺 at the University of Trento 🇮🇹 and the University of Tübingen 🇩🇪
advised by Elisa Ricci and Matthias Bethge.
I am also really fortunate to have Massimiliano Mancini as a co-advisor.
Before starting my PhD, I got both my BS/MS from the University of Trento.
|

|
Research Interests🔭 Currently. My work revolves around Large Multimodal Foundation Models, integrating diverse modalities such as Images, Videos, and Language. I am especially interested in pretraining, with emphasis on Data-Centric aspects. In a parallel research thread, I focus on zero-shot, few-shot (and/or in-context, you name it :)), and test-time generalization and learning. ⌛️ Previously. I worked on Model Compression sponsored by a research gift from Cisco Research. During my MS, I was a Research Intern with Elisa Ricci, Federica Arrigoni (University of Trento), working with Luca Magri (Politecnico di Milano) and Vladislav Golyanik (Max Planck Institute for Informatics) on Quantum Computer Vision. |
Publications & Preprints |
|
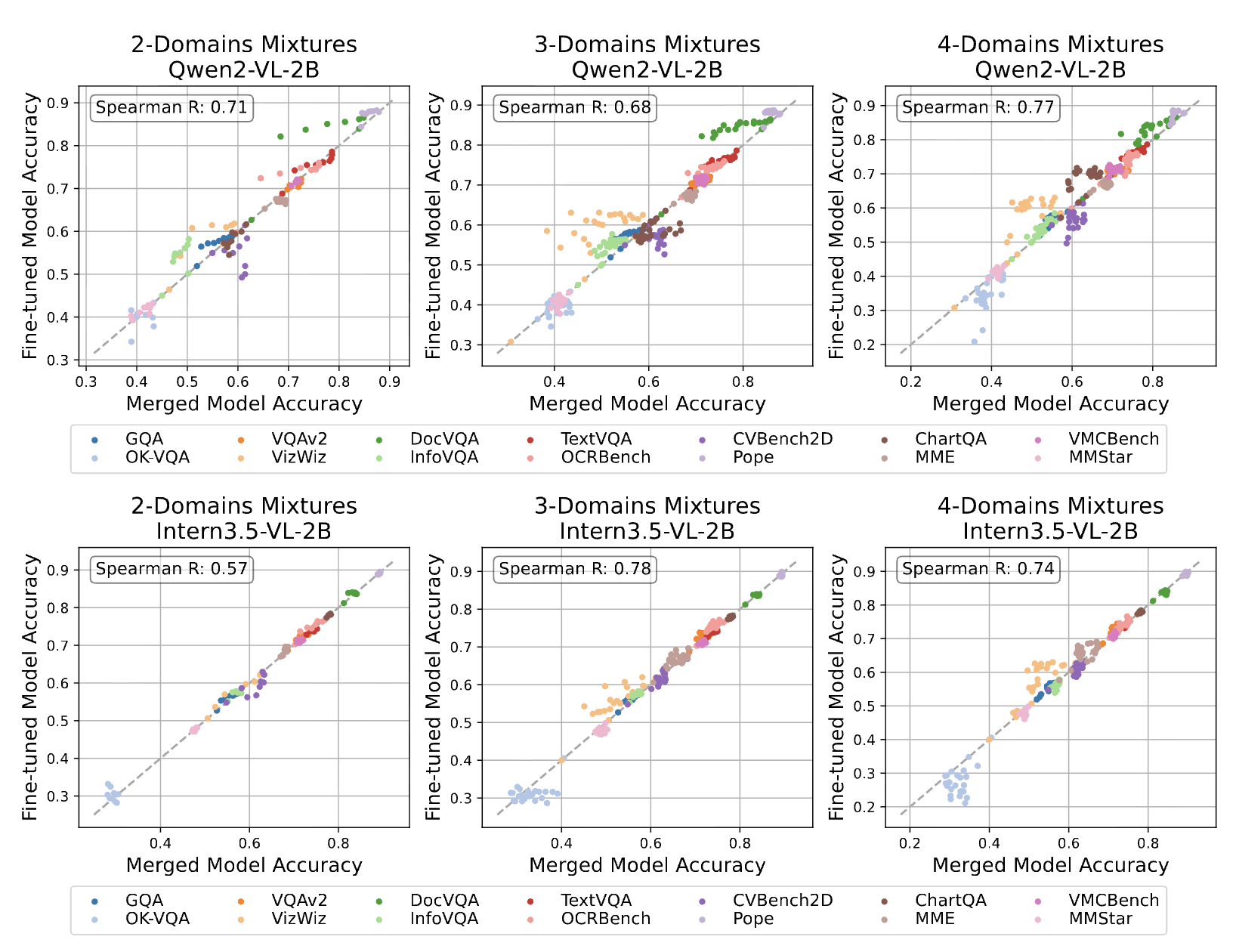
Linear Model Merging Unlocks Simple and Scalable Multimodal Data Mixture Optimization
Davide Berasi, Matteo Farina, Massimiliano Mancini and Elisa Ricci arXiv PrePrint, Feb 2026. arXiv / Code tl;dr. We show that model merging, i.e., interpolating domain-specific experts in parameter space, is a surprisingly accurate and cheap proxy for evaluating data mixtures. The key insight is that mixture weights and merging weights are interchangeable: optimizing one often near-optimizes the other. This cuts the search cost to just one training run per domain, turning a costly combinatorial problem into a tractable one. |
|
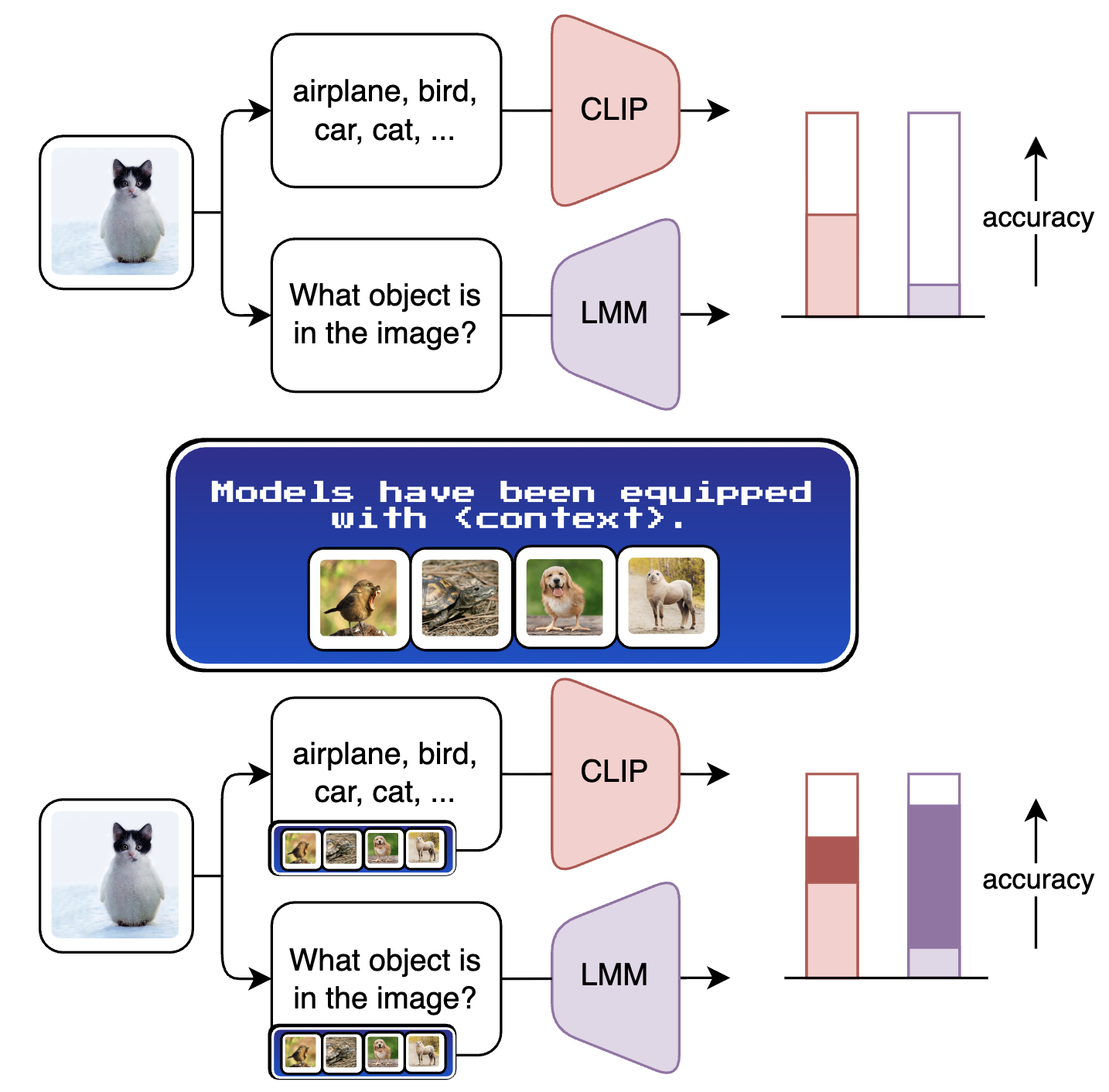
Large Multimodal Models as General In-Context Classifiers
Marco Garosi, Matteo Farina, Alessandro Conti, Massimiliano Mancini and Elisa Ricci CVPR 2026 (Findings) arXiv / Code tl;dr. We argue that existing evidence that LMMs are bad at closed-world discriminative tasks overlooks an important capability: In-Context Learning (ICL). We show that ICL makes LMMs close the gap with CLIP models with as little as 8 or 16 in-context examples. We then show that CIRCLE, a simple leave-one-out in-context refinement, opens the door to successful open-world recognition as well. |
|
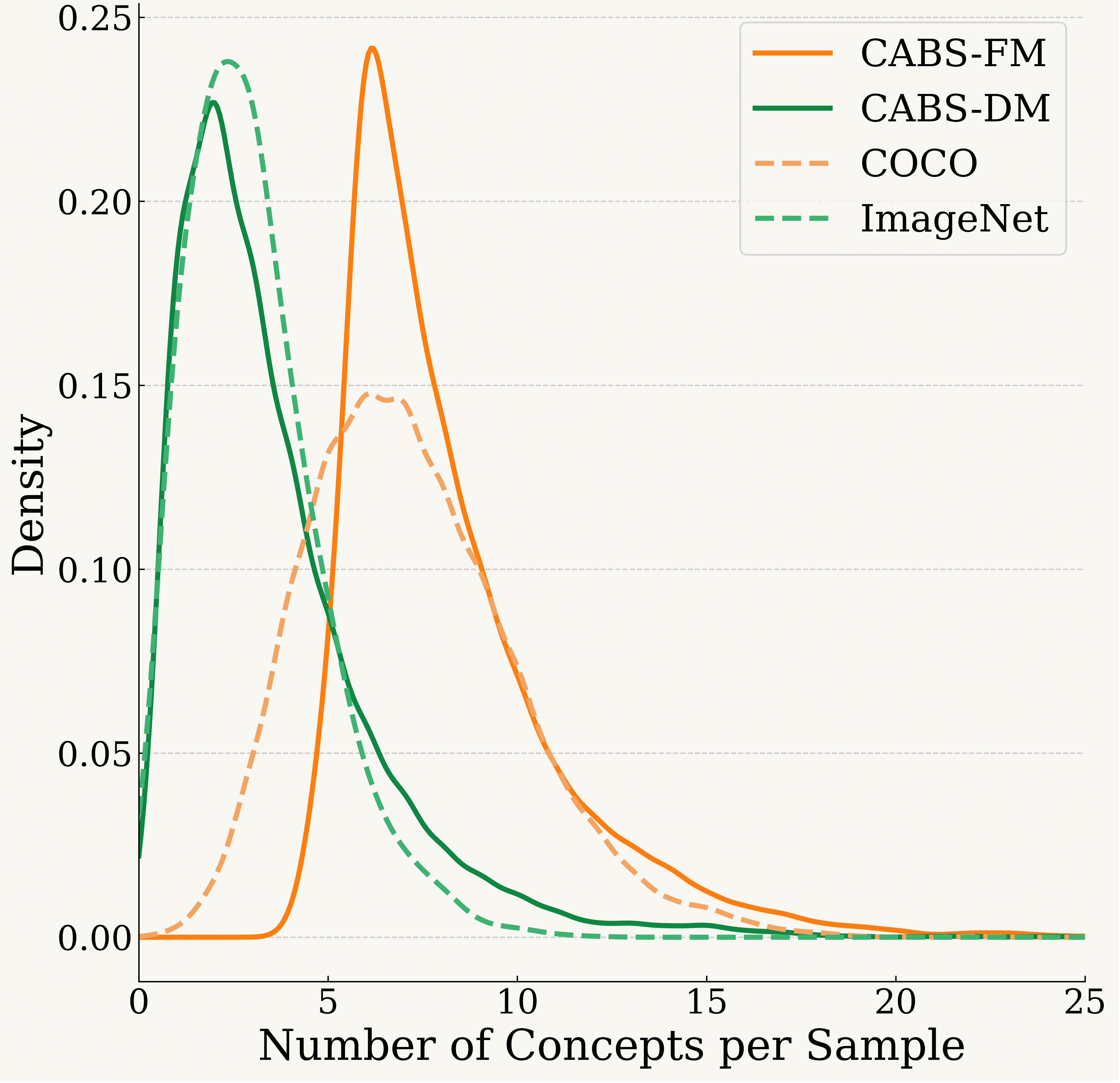
Concept-Aware Batch Sampling Improves Language-Image Pretraining
Adhiraj Ghosh, Vishaal Udandarao*, Thao Nguyen*, Matteo Farina*, Mehdi Cherti, Jenia Jitsev, Sewoong Oh, Elisa Ricci, Ludwig Schmidt and Matthias Bethge CVPR 2026, *denotes equal core contribution Tweet / arXiv / Code tl;dr. We introduce DataConcept, 128M image-text pairs annotated with concept-centric information, and Concept-Aware Batch Sampling (CABS), a framework to use concept information to curate batches online instead of static curation. Motivated by the observation that ImageNet and COCO training sets exhibit substantially different concept compositions, we propose 2 variants of CABS, i.e., Diversity & Frequency Maximization, yielding boosts up to +7% and +9% on zero-shot clf and retrieval benchmarks, respectively. |
|
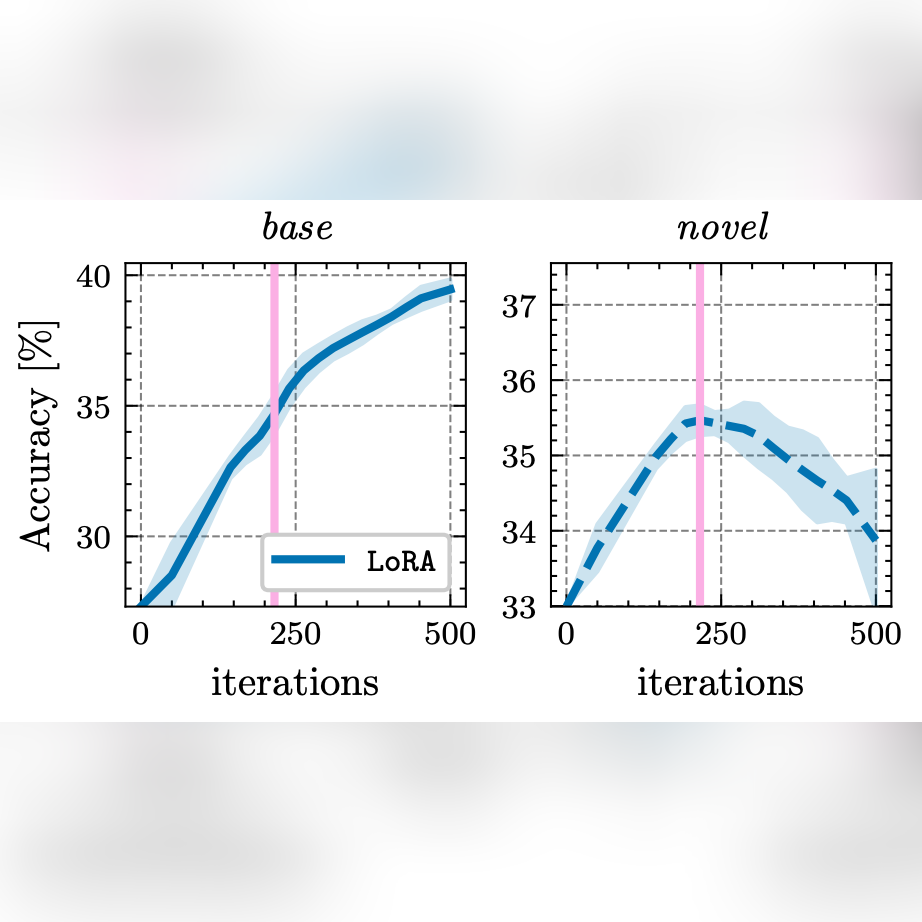
Rethinking Few-Shot Adaptation of Vision-Language Models in Two Stages
Matteo Farina, Massimiliano Mancini, Giovanni Iacca and Elisa Ricci CVPR 2025 arXiv / Code tl;dr. We empirically show that the learning dynamics of PEFT techniques typically used for Few-Shot Learning naturally splits into two distinct stages: task- / domain-level feature extraction, and specialization to the annotated categories (≠ overfitting). We then show that a simple linear classifier trained after stage 1 consistently achieves state-of-the-art results, thereby largely simplifying FSL. |
|
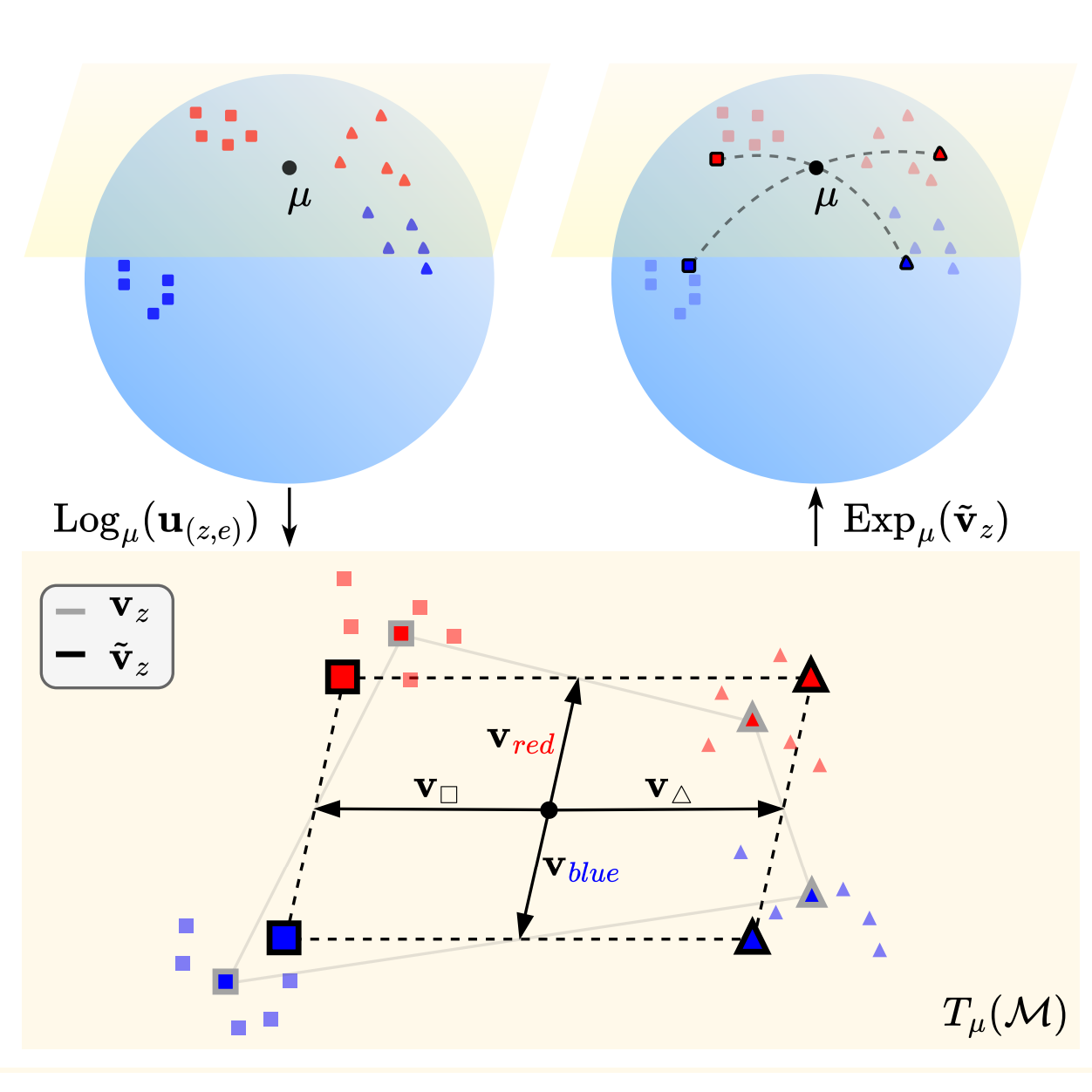
Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models
Davide Berasi, Matteo Farina, Massimiliano Mancini, Elisa Ricci and Nicola Strisciuglio CVPR 2025 ✨ Highlight arXiv / Code tl;dr. This work investigates the existence of compositional structures in sets of visual embeddings. We observe that a linear structure (successfully used for textual embeddings in prior work) fails for visual inputs, but one can nevertheless use it on a plane tangent to a "decomposition context" lying on a manifold of arbitrary shape (for CLIP, this is a hyper-spherical one). Surprisingly, this Geometry-Aware framework outperforms task-specific solutions for Group Robustness and optimizes for controllable image generation. |

|
Frustratingly Easy Test-Time Adaptation of Vision-Language Models
Matteo Farina, Gianni Franchi, Giovanni Iacca, Massimiliano Mancini and Elisa Ricci NeurIPS 2024 Tweet / arXiv / Code tl;dr. We challenge the widely accepted Marginal Entropy Minimization (MEM) approach for single-test-point Test-Time Adaptation (TTA), which operates by augmenting, marginalizing, and minimizing entropy. We demonstrate that simple majority voting (or "adapting" by setting the softmax temperature to "zero") consistently outperforms established methods, providing a strong and cheap baseline for TTA. |
|
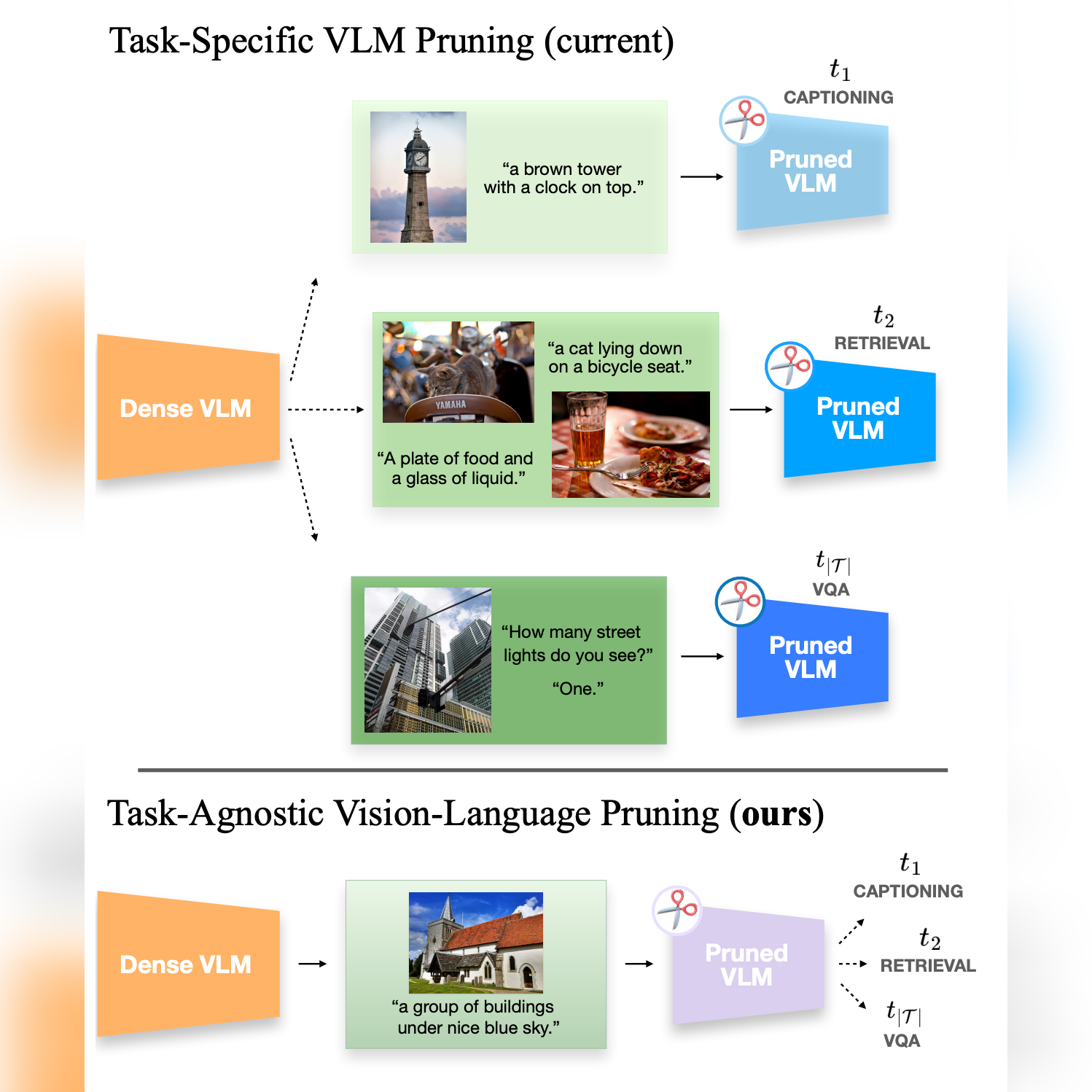
Multiflow: Shifting Towards Task-Agnostic Vision-Language Pruning
Matteo Farina, Massimiliano Mancini, Elia Cunegatti, Gaowen Liu, Giovanni Iacca, and Elisa Ricci CVPR 2024 Tweet / arXiv / Code tl;dr. We investigate the existence of transferable lottery tickets within Vision-Language Models, i.e., pruned networks that optimize for unknown downstream tasks. We benchmark 8 pruning methods on 2 VLMs and 3 Vision-Language Tasks (Captioning, VQA, Retrieval) and introduce a simple algorithm that improves transfer by integrating neuron importance into weight saliency and balancing the contribution of different modalities. |
|
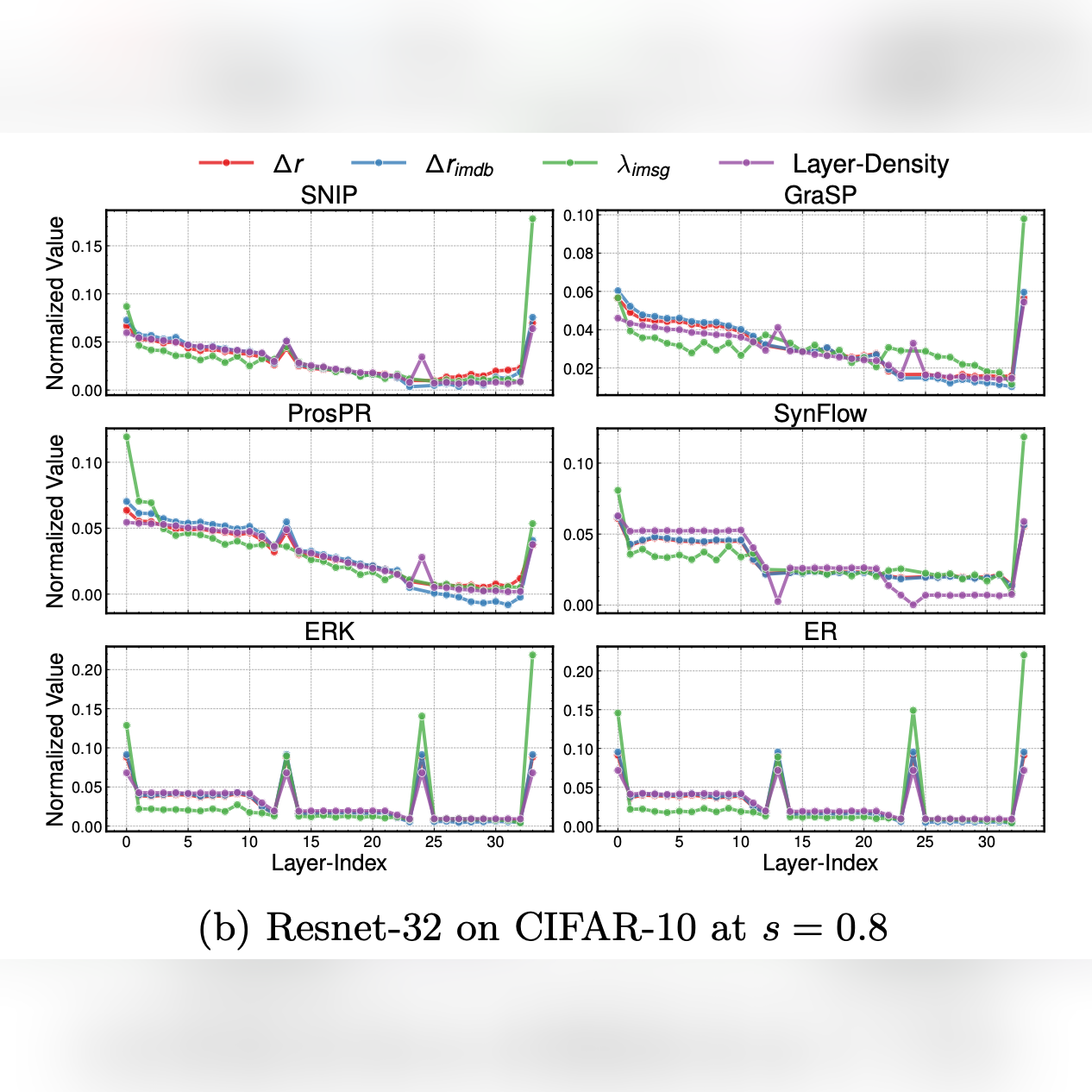
Understanding Sparse Neural Networks from their Topology via Multipartite Graph Representations
Elia Cunegatti, Matteo Farina, Doina Bucur, and Giovanni Iacca TMLR, April 2024 Tweet / arXiv / Code tl;dr. We empirically show (over 1000+ sparse networks) that previous metrics to predict the performance of Sparse NNs are no better than the naive layer-wise density. We introduce an end-to-end graph encoding that captures model-input interactions, from which a broader spectrum of topological metrics can be extracted. We further show that a mixture of metrics is more informative than established encodings/metrics pairings. |

|
Quantum Multi Model Fitting
Matteo Farina, Luca Magri, Willi Menapace, Elisa Ricci, Vladislav Golyanik, and Federica Arrigoni CVPR 2023 ✨ Highlight arXiv / Code tl;dr. We leverage Quantum Annealers (QAs) to tackle the NP-Hard problem of fitting multiple parametric models to (possibly) outlier-contaminated data, aka Multi Model Fitting (MMF). To do so, we provide a simple mathematical reformulation of MMF as a set-coverage problem for QAs. We further introduce an iterative decomposition scheme which empirically scales to 1000+ qbits reliably. |
|
|